今天给大家分享下Java Class字节码文件的结构解析。(文末附有详细大图)
代码
首先我们创建一个Java类,然后添加一些成员变量和方法,如下:
public class Test {
String name = "hello";
int size = 10;
long num = 100;
Double pi = 3.14;
public static void main(String[] args) {
Test test = new Test();
test.print();
}
public void print() {
System.out.print(name);
}
}大家可以看到,这是一个非常简单的类,仅仅有几个基本类型的成员变量和两个简单的方法。这是为了我们分析Class文件方便起见,没有添加复杂的结构。
编译
然后大家可以用javac命令编译一下这个类。编译之后,我们就得到了一个class文件,用sublime之类的软件打开这个class文件,我们可以看到如下信息:
CA FE BA BE 00 00 00 34 00 40 0A 00 11 00 29 08
00 2A 09 00 0C 00 2B 09 00 0C 00 2C 05 00 00 00
00 00 00 00 64 09 00 0C 00 2D 06 40 09 1E B8 51
..........
00 00 00 0C 00 01 00 00 00 0B 00 1F 00 20 00 00
00 01 00 27 00 00 00 02 00 28 是一行一行的十六进制的字符,每两个字符是一个字节,每个字节之间用空格分隔,我省略掉了中间的多行数据,如果要看完整数据,请看文末。
这些就是编译之后的信息了,文件中的字符在我们看来只是一行一行字符,其实是划分格式的。我们来看一下是如何划分的。
结构
Class文件的结构,是一个结构体,有以下元素,描述如下:
ClassFile {
u4 magic; //魔数
u2 minor_version; //Java的次版本号
u2 major_version; //Java的主版本号
u2 constant_pool_count; //常量池的长度
cp_info constant_pool[constant_pool_count]; //常量池数组
u2 access_flags; //类访问标志
u2 this_class; //类名索引
u2 super_class; //父类名索引
u2 interface_count; //实现的接口的数量
u2 interfaces[interface_count]; //接口数组
u2 fields_count; //字段数量
field_info fields[fields_count]; //字段数组
u2 methods_count; //方法数量
method_info methods[methods_count]; //方法数组
u2 attributes_count; //属性数量
attribute_info attributes[attributes_count]; //属性数组
}左边u2,u4都是表示字节的长度,u2是两字节,u4是四字节。右边是元素的名称。
Class文件就是由以上元素,一个紧挨一个组成的。总体的结构还是不复杂的,开头的三个值,magic,minor_version,major_version和中间的access_flags,this_class,super_class,他们是固定的位置,固定的字节长度。其他的数量不一定的值,都是一个长度,然后后面就是紧跟着该长度的数组,存储着该组值。数组结构通常都有下一级的子结构。
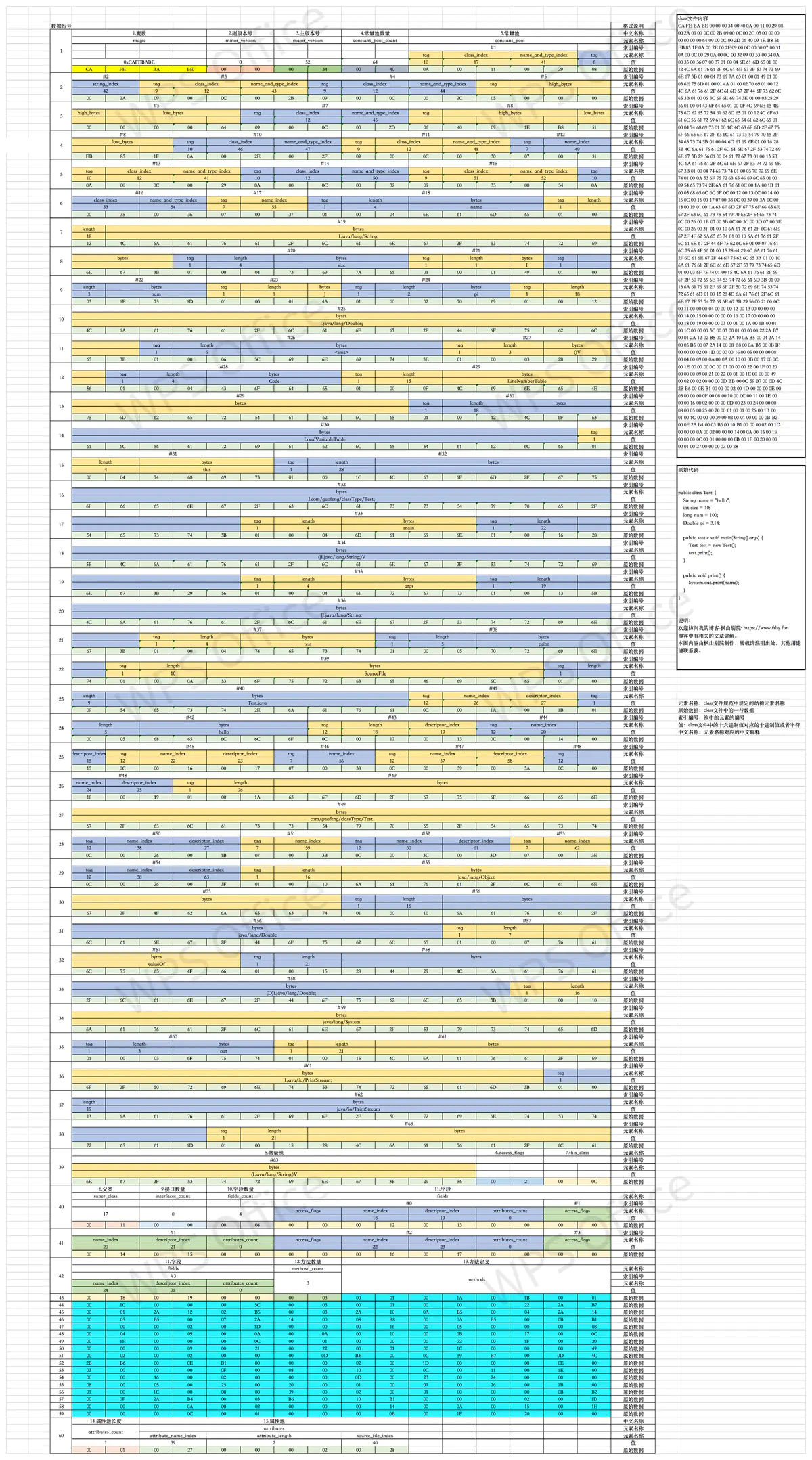
我把字节文件按照上面的元素格式,以不同的颜色划分了出来,请大家看下结构图: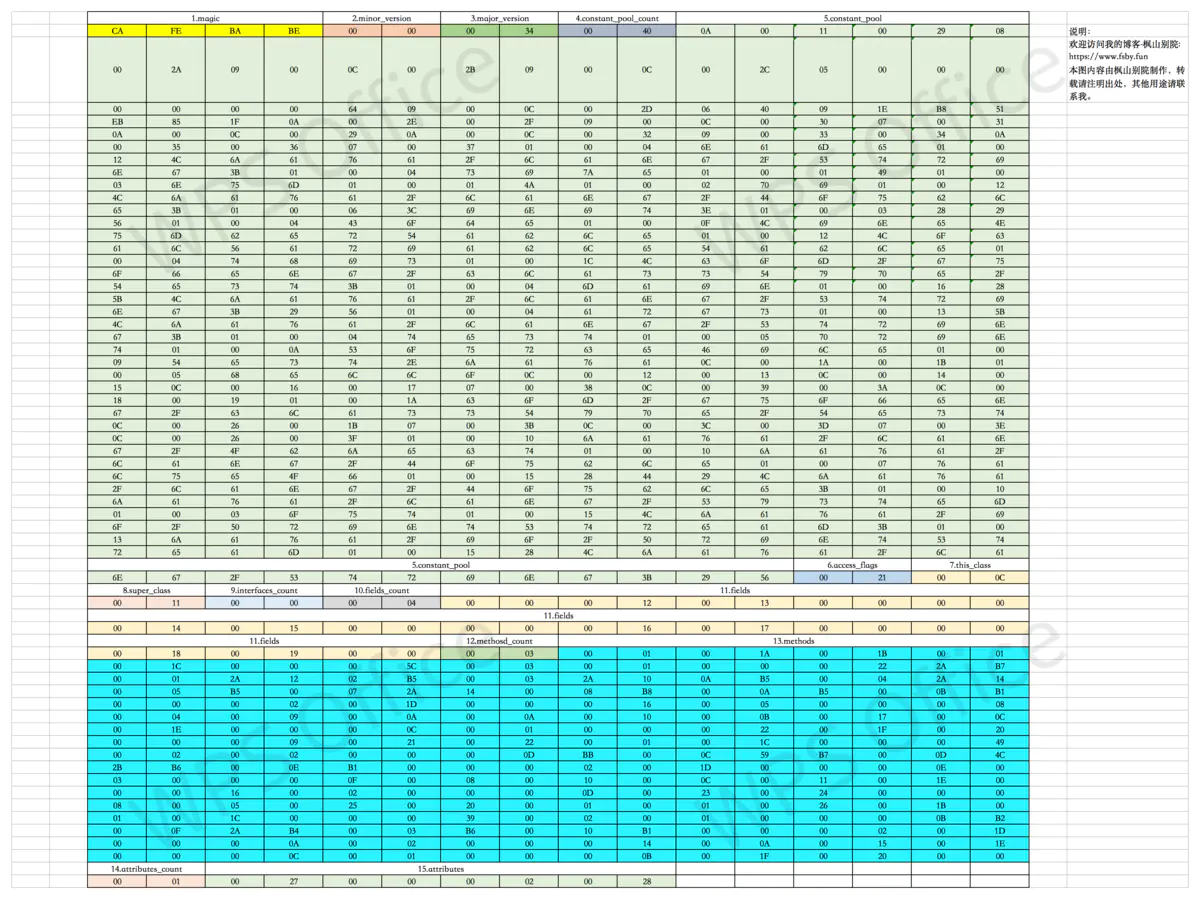
看图非常的一目了然,读两遍书,不如看一遍图啊。
连续的相同颜色的格子,是同一种元素的值。元素之间是紧紧的排列在一起,大家可以看到结构非常的紧凑,节省空间。看不清的同学可以下载下来,放大一下看。
分析
1. magic 魔数
我们知道有时候通过后缀识别文件是不准确的,因为很容易就改掉后缀。所以很多文件格式,在文件的开头写上几个固定的值,为了识别方便该种格式。比如PDF文件的开头是“%PDF”,这个固定的值,就叫魔数,其实就是个标识。class文件的魔数就是“CA FE BA BE”,JVM读取开头的四个字节,如果是这个值,那么就认为这个文件是个class。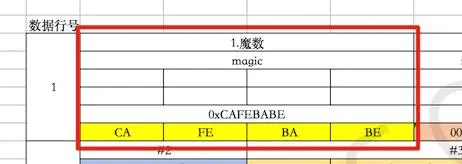
2. version 版本号
魔数之后,是版本号,大家可以看到,我们有两部分的版本号。第一个版本号就是次版本号,第二个是主版本号。比如52.0,52是主版本号,0是次版本号。这个版本是为了让JVM识别编译这个clas文件的Java版本,比如Java SE8,对应的版本号是52.0,Java SE7 是51.0,Java SE6 是50.0。如果一个最高只支持Java SE7版本的JVM,读取到一个52.0,那么它可能是执行不了这个class的,以为它是Java SE8编译出来的,可能用了JavaSE8的新特性。
3. constant_pool 常量池
常量池占用了class中非常多的空间,存放着非常多的信息,包括数字,字符串,类和接口的名字,字段和方法的名字等等。上来先是常量池的数量,也就是常量池数组的长度。后面紧跟着就是数组的内容,非常长,结构也不太一样。大家可以仔细看看附录中的详细图,太大了,在这就不截图了。
常量池中元素的子结构虽然有非常多的种类,但是都差不多的。首先是tag,tag的值表示这个元素是一个什么类型,也就是一个什么数据结构,然后JVM就可以根据这个结构来解析数据了。一般的XXX_index就是一个索引,length就是一个长度,bytes中是该元素存储的值。结构非常多,我们后面单独一篇文章介绍下这里。
4. access_flags 类访问标志
access_flags保存的信息是,该类的访问标志,比如是public还是private,是个接口还是个类,或者枚举,等等。
此处access_flags的值是0x0021,代表什么意思呢?我们需要看个表格:
| 名称 | 值 | 说明 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public类型 |
| ACC_FINAL | 0x0010 | final修饰符 |
| ACC_SUPER | 0x0020 | 使用invokespecial字节码指令,在JDK1.2之后添加 |
| ACC_INTERFACE | 0x0200 | 接口 |
还有好几种类型,我们就先看这些。我们的值是0x0021,好像没有这个值对应的类型。其实是,0x0020 加上 0x0001,也就是说0x0021表示ACC_PUBLIC和ACC_SUPER。也就是说,这是个public访问级别的类。
5. this_class 类名索引
this_class元素保存的是类的全限定类名,即包路径加类名。为什么还有个索引呢?因为这个地方保存的不是具体的全限定类名的字符串,是一个索引值。这个索引是常量池的索引,也就是说,其实真正的全限定类名字符串是在常量池存着呢。我们在附录的详细表中找一下这个值,找到第39行数据的最后,是this_class的位置。
它的值是0x000c,是十进制的12对吧?我们找常量池中的索引是12的值,在第4行最后。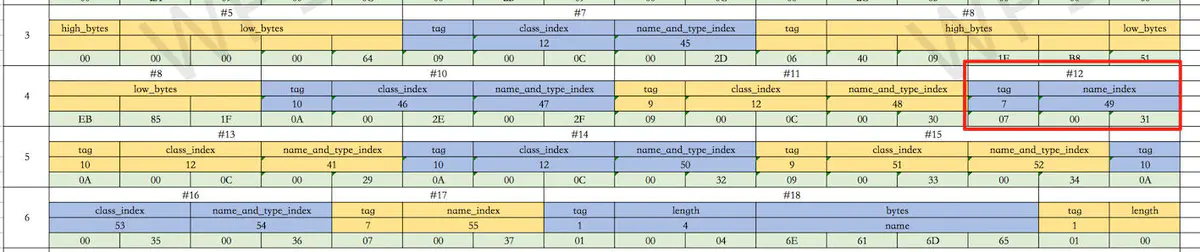
很奇怪,这个地方比不是我们说的全限定类名字符串,是一个叫name_index的索引。其实这个位置存放的数据,是有一个子结构的,它由tag和name_index组成。tag的值是7,这个值7代表了一种数据结构,就是CONSTANT_Class_info,这个类型保存的值是类或者接口的符号引用。又是一个引用,也就是索引。从表上我们可以知道,这个索引的值是49,OK,我们再从常量池找索引49的值。
在第26和27行上,我们终于找到了类的全限定名称。
6. super_class 父类名索引
super_class跟this_class是一样的,不过这里保存的是类的父类全限定名称而已。大家可以自己找一下看看。不过需要注意的是,如果没有明确指定某个类的父类,在Java中默认父类都是java.lang.Object,而java.lang.Object本身是没有父类的,所以如果是Object类,它的super_class值就是0。
7. interfaces 接口池
接着就是接口索引表或者说是接口池了,这里保存类实现的接口。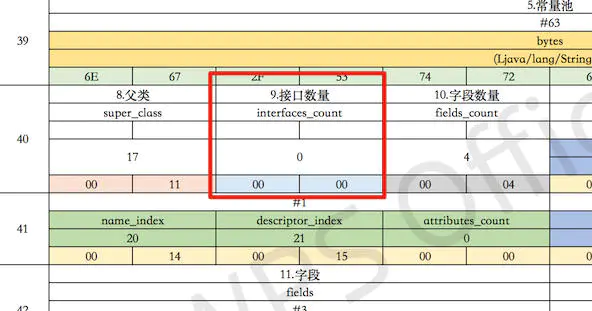
因为我们的类没有实现接口,所以它的长度是0,后面的数组自然也就省略了。
8. fields 字段池
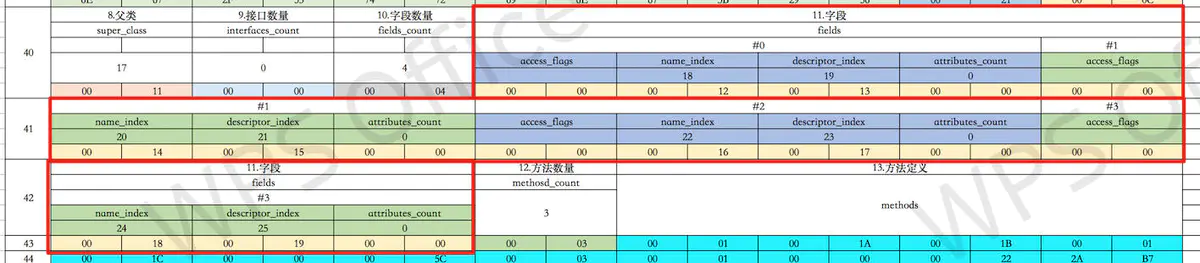
接着是我们的字段信息。从 fields_count的值我们可以知道有4个字段,这跟我们在代码中的字段数量是一致的。然后紧接着就是字段数组了。字段数组中的元素是有数据结构的。如下:
field_info {
u2 access_flags; //变量的访问标识符
u2 name_index; //名称索引
u2 descriptor_index; //类型信息索引
u2 attributes_count; //自定义属性长度
attribute_info attributes[attributes_count]; //自定义属性池
}name_index中存的就是字段名字的索引,老规矩大家自己找一下。access_flags是变量的访问标识符,descriptor_index保存的是变量的类型信息。最后剩下的属性,为什么有了类的属性池还会在这里有个字段下的属性池呢?这个字段下的属性池是留给JVM来自定义拓展的,各个JVM实现可能会不一样,JVM遇到识别不了的属性会自动跳过。
9. methods 方法池
大家可以看到,在附录详细大图中,方法池没有展开详细的结构,这是因为这里太复杂了,展开图不太好画,我太懒了,所以没画,哈哈哈哈。依然是上来就是一个长度,3个方法,后面跟着一个数组。有人要问了,不对啊,怎么是3个方法,我们只写了2个。那是因为还有个类的默认构造方法,忘了吧,哈哈。后面有机会我们详细分析方法池的结构。
10. attributes 属性池
属性池这个地方,跟常量池一样,保存了很多信息,不过我们这个类中的属性信息较少。属性也有很多的子结构,而且不同的JVM实现还可能会有自己的属性值,这里我们后面有机会单独说一下,大家现在知道即可。
附录
最后,附上一张非常详细的大图,我在图中画出了更详细的结构,包括常量池中子元素的结构,每个字节对应的值是什么等等,非常详细,也耗费了我很多时间,希望对大家有用。大家可以下载下来,经常看一看。